We’ve become very good at designing context for AI systems.
We remove irrelevant files. We isolate the problem. We reduce noise. We structure instructions carefully.
We do this because we understand something fundamental:
Context quality determines outcome quality.
But there’s an asymmetry.
We apply this discipline to agents. We rarely apply it to each other.
Think about the last PR you reviewed.
- How many files did it change?
- How many distinct concerns were mixed together?
- Did you fully understand it — or did you approximate parts of it?
Here’s the uncomfortable part:
The bigger the PR, the less likely you are to give it 100% of your attention. Especially if you’ve got five more waiting in your queue.
This isn’t laziness.
It’s cognitive load.
Working memory is finite. Attention is finite. Review bandwidth is finite.
When a change exceeds that budget, something shifts.
You stop deeply understanding. You start approximating.
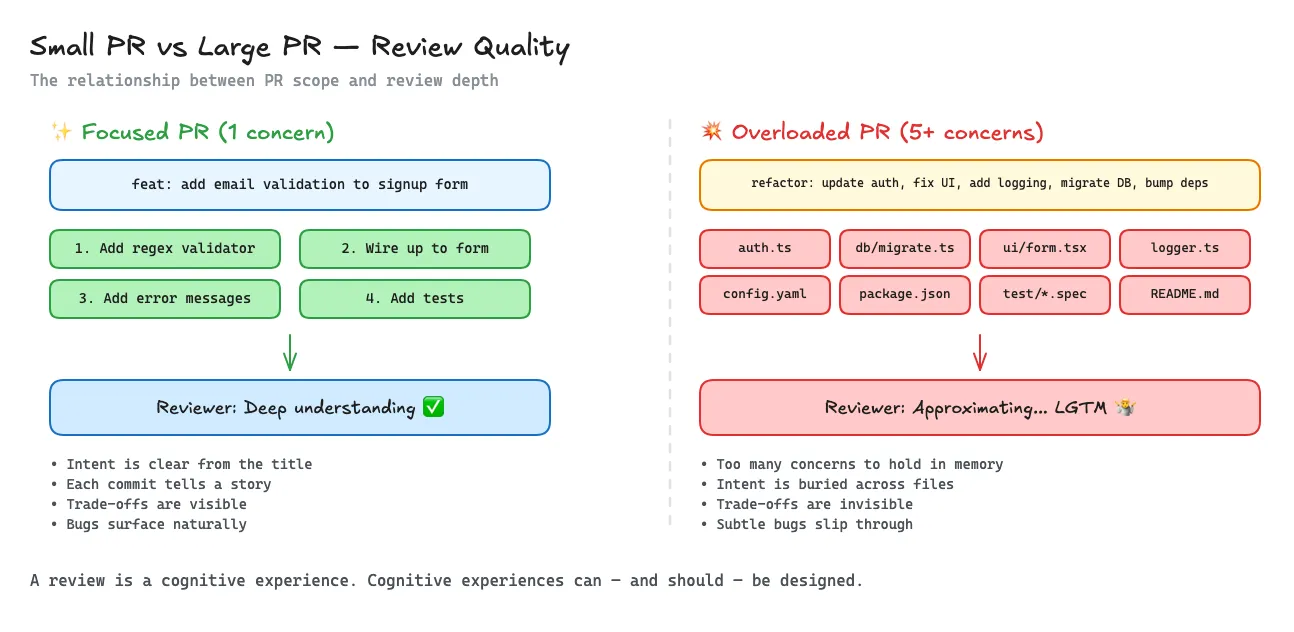
While some parts of the industry are moving toward fully AI-driven development, the vast majority of software will remain AI-augmented.
In highly regulated environments — healthcare, finance, infrastructure — human review will remain part of the delivery chain.
Which means this problem isn’t going away.
If anything, the ability to engineer context for human reviewers becomes more important.
If humans remain in the loop, the quality of the context we give them becomes a first-order engineering concern.
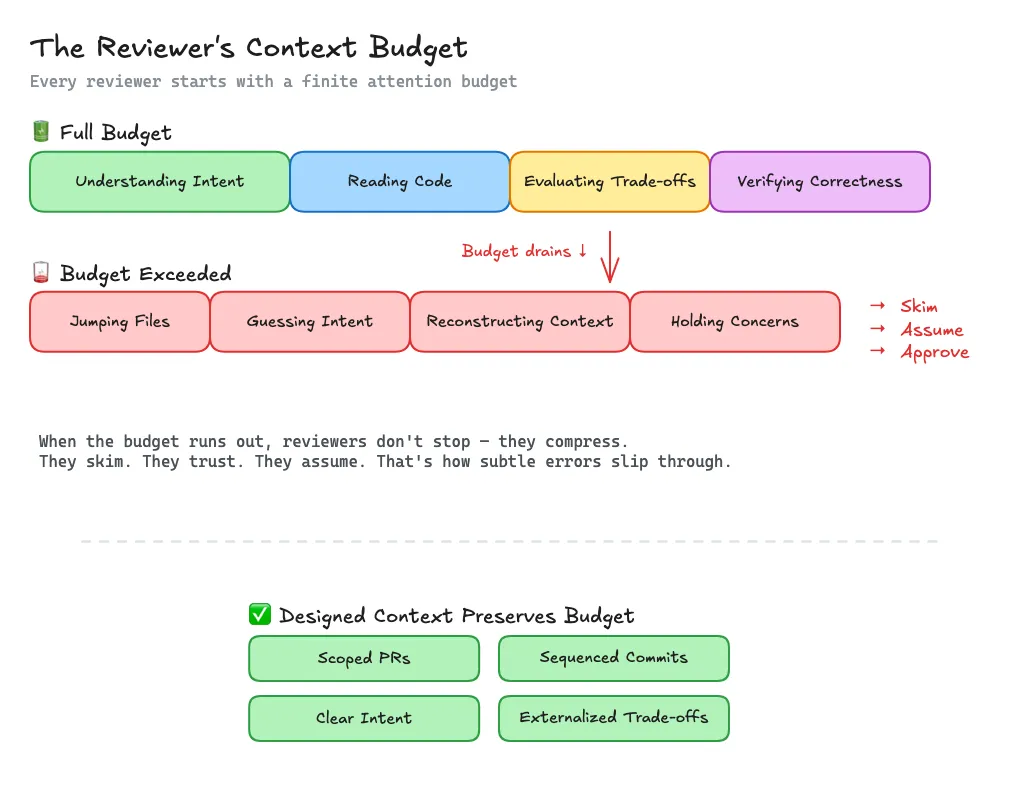
A Model: Context Budget
Every reviewer has a context budget.
It gets spent on:
- jumping across files
- reconstructing intent
- guessing trade-offs
- holding multiple concerns in working memory
When the budget runs out, people don’t stop reviewing.
They compress.
They skim. They trust. They assume.
That’s how subtle errors slip through.
The Thoughtful Engineer
You’ve worked with them.
Their PRs are scoped tightly. Their commits are sequenced intentionally.
Sometimes you can review commit-by-commit and the story unfolds cleanly.
You don’t feel like you’re decoding something.
You feel like you’re reading a story and going along for the ride.
There’s a clear beginning. A clear intent. A clear set of trade-offs.
They understand something subtle:
A review is a cognitive experience. And cognitive experiences can and should be designed.
A Simple Checklist
Before opening (or approving) a PR:
- Can I explain this change in one sentence?
- Does this PR contain more than one conceptual concern?
- Does this PR contain multiple changes that could stand on their own?
- Would reviewing commit-by-commit reduce cognitive load?
- Did I externalize the trade-offs instead of keeping them in my head?
If any of these feel uncomfortable, the diff might be too large.

If we are willing to engineer context for agents, it’s probably time we engineer context for humans too.
I’m curious:
What’s the average PR size in your team? And do you think it affects review quality?